- Published on
- Updated on
Генерирующий GC в Python и Ruby
- Authors
Эта публикация - перевод статьи. Ее автор - Pat Shaughnessy. Оригинал доступен по ссылке ниже:
На прошлой неделе я написал свою первую половину своих заметок из презентации, которую я сделал в RuPy под названием «Визуализация коллекции мусора в Ruby и Python». Я объяснил, как стандартный Ruby (также известный как Ruby Interpreter или MRI Matz) использует сборку мусора ( GC), называемый mark и sweep, тот же базовый алгоритм, разработанный для оригинальной версии Lisp в 1960 году. Мы также видели, как Python использует совсем другой алгоритм GC, также изобретенный 53 года назад под названием подсчета ссылок.
Как оказалось, наряду с подсчетом ссылок Python использует второй алгоритм, называемый коллекцией мусора . Это означает, что сборщик мусора Python обрабатывает вновь созданные объекты по-другому, чем старые. И начиная с версии предстоящей версии 2.1, MRI Ruby также будет использовать GC поколения GC впервые. (Две альтернативные версии Ruby, JRuby и Rubinius уже много лет используют коллекцию мусора для создания мусора. Я расскажу о том, как на RubyConf на JRuby и Rubinius будет работать сборка мусора на следующей неделе).
Конечно, фраза «обрабатывает новые объекты по-разному от более старых» - это немного размахивает руками. Что такое новые и старые объекты? Точно как Ruby и Python обрабатывают их по-разному? Сегодня я буду продолжать описывать работу этих двух сборщиков мусора и отвечать на эти вопросы. Но прежде чем мы перейдем к генерации GC, нам сначала нужно узнать больше о серьезной теоретической проблеме с алгоритмом подсчета ссылок Python.
Циклические структуры данных и подсчет ссылок в Python
В прошлый раз мы видели, что Python использует целочисленное значение, сохраненное внутри каждого объекта, называемое счетчиком ссылок , для отслеживания того, сколько указателей ссылается на этот объект. Всякий раз, когда переменная или другой объект в вашей программе начинает ссылаться на объект, Python увеличивает этот счетчик; когда ваша программа перестает использовать объект, Python уменьшает счетчик. Когда счетчик ссылок становится равным нулю, Python освобождает объект и восстанавливает свою память.
Начиная с 1960-х годов, компьютерные ученые знают о теоретической проблеме с этим алгоритмом: если одна из ваших структур данных ссылается на себя, если это циклическая структура данных , некоторые подсчеты ссылок никогда не станут нулевыми. Чтобы лучше понять эту проблему, давайте возьмем пример. В приведенном ниже коде показан тот же класс Node, который мы использовали на прошлой неделе:

У нас есть конструктор (они называются __init__ в Python), который сохраняет один атрибут в переменной экземпляра. Ниже определения класса мы создаем два узла, ABC и DEF, которые я представляю с помощью прямоугольников слева. Счетчик ссылок внутри обоих наших узлов изначально один, поскольку один указатель ( n1 и n2 , соответственно) относится к каждому узлу.
Теперь давайте определим два дополнительных атрибута в наших узлах: next и prev:
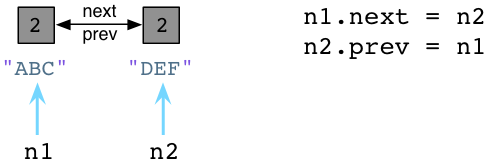
В отличие от Ruby, используя Python, вы можете определить переменные экземпляра или атрибуты объектов на лету, как это. Это похоже на немного интересную магию, отсутствующую в Ruby. (Отказ от ответственности: я не разработчик Python, поэтому у меня может быть некоторая номенклатура.) Мы установили n1.next в ссылку n2 и n2.prev, чтобы указать на n1 . Теперь наши два узла образуют двусвязный список, используя круговой шаблон указателей. Также обратите внимание, что подсчет ссылок как ABC, так и DEF увеличился до двух. Есть два указателя, относящихся к каждому узлу: n1 и n2, как и раньше, а теперь и следующий и предыдущий .
Теперь давайте предположим, что наша программа Python перестает использовать узлы; мы устанавливаем n1 и n2 равными нулю. (В Python null известен как None .)

Теперь Python, как обычно, уменьшает счетчик ссылок внутри каждого узла до 1.
Генерация нуля в Python
Обратите внимание, что на диаграмме выше мы столкнулись с необычной ситуацией: у нас есть «остров» или группа неиспользуемых объектов, которые ссылаются друг на друга, но не имеют внешних ссылок. Другими словами, наша программа больше не использует объект-узел, поэтому мы ожидаем, что сборщик мусора Python будет достаточно умным, чтобы освободить оба объекта и вернуть их память для других целей. Но этого не происходит, потому что оба отсчета ссылок равны единице, а не нулю. Алгоритм подсчета ссылок Python не может обрабатывать объекты, которые ссылаются друг на друга!
Конечно, это надуманный пример, но ваши собственные программы могут содержать круговые ссылки, подобные этому, тонким способом, о котором вы, возможно, и не подозреваете. Фактически, по мере того как ваша программа Python работает со временем, она создаст определенное количество «плавающих мусора», неиспользуемых объектов, которые собиратель Python не сможет обработать, потому что подсчет ссылок никогда не достигает нуля.
Именно в этом заключается алгоритм генерации Python! Так же, как Ruby отслеживает неиспользуемые, свободные объекты, используя связанный список ( бесплатный список ), Python использует другой связанный список для отслеживания активных объектов. Вместо того, чтобы называть это «активным списком», внутренний C-код Python относится к нему как Generation Zero . Каждый раз, когда вы создаете объект или какое-либо другое значение в своей программе, Python добавляет его в связанный список Generation Zero:
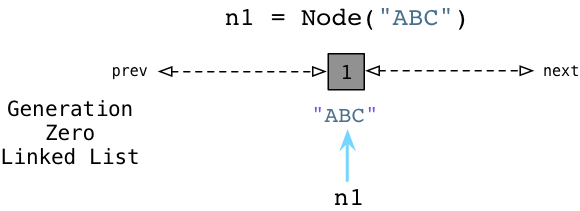
Выше вы можете видеть, когда мы создаем узел ABC, Python добавляет его в Generation Zero. Обратите внимание, что это не фактический список, который вы видите и получаете в своей программе; этот связанный список полностью является внутренним для среды выполнения Python.
Аналогично, когда мы создаем узел DEF, Python добавляет его в тот же связанный список:
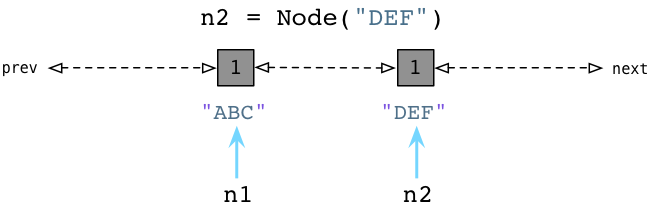
Теперь Generation Zero содержит два узла. (Он также будет содержать все другие значения, которые создает наш код Python, и многие внутренние значения, используемые самим Python.)
Обнаружение циклических ссылок
Позже Python перебирает объекты в списке Zero Generation и проверяет, к каким другим объектам относится каждый объект в списке, уменьшая количество отсчетов ссылок по мере их поступления. Таким образом, Python учитывает внутренние ссылки от одного объекта к другому, что помешало Python освобождать объекты раньше.
Чтобы сделать это немного легче понять, давайте возьмем пример:
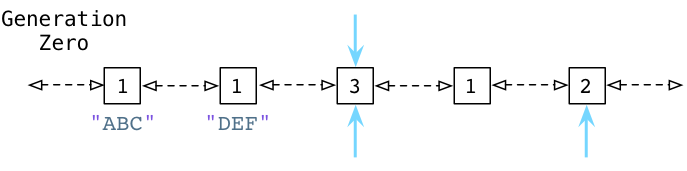
Выше вы можете видеть, что узлы ABC и DEF содержат счетчик ссылок 1. Три других объекта также находятся в связанном списке Generation Zero. Синие стрелки указывают, что некоторые объекты ссылаются на другие объекты, которые находятся где-то в другом месте - ссылки из-за пределов поколений. (Как мы сейчас увидим, Python также использует два других списка под названием Generation One и Generation Two.) Эти объекты имеют более высокий счетчик ссылок из-за других указателей, ссылающихся на них.
Ниже вы можете увидеть, что происходит после того, как Python собирает сборщики мусора Generation Zero.
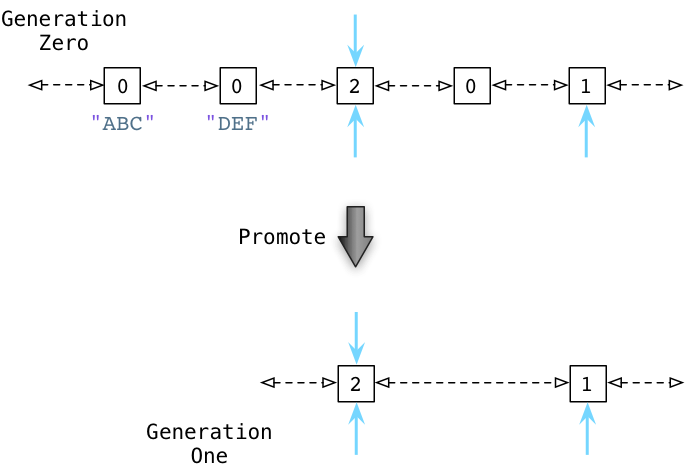
Определяя внутренние ссылки, Python может уменьшить количество ссылок на многие объекты Generation Zero. Выше в верхнем ряду вы можете видеть, что ABC и DEF теперь имеют счетчик ссылок, равный нулю. Это означает, что коллекционер освободит их и вернет им память. Оставшиеся живые объекты затем переносятся в новый связанный список: Generation One.
В некотором смысле алгоритм GC Python похож на алгоритм метки и развертки, используемый Ruby. Периодически он отслеживает ссылки с одного объекта на другой, чтобы определить, какие объекты остаются в живых, активные объекты, которые наша программа все еще использует - точно так же, как процесс маркировки Ruby.
Пороги сбора мусора в Python
Когда Python выполняет этот процесс маркировки? По мере запуска вашей программы Python интерпретатор отслеживает, сколько новых объектов он выделяет, и сколько объектов оно освобождает из-за нулевого количества ссылок. Теоретически эти два значения должны оставаться одинаковыми: каждый новый объект, созданный вашей программой, должен в конечном итоге быть освобожден.
Конечно, это не так. Из-за циклических ссылок и потому, что ваша программа использует некоторые объекты дольше, чем другие, разница между подсчетом распределения и количеством выпуска медленно растет. Как только это значение дельты достигнет определенного порога, сборщик Python запускается и обрабатывает список Generation Zero, используя вышеприведенный алгоритм вычитания, освобождая «плавающий мусор» и перемещая оставшиеся объекты в Generation One.
Со временем объекты, которые ваша программа Python продолжает использовать в течение длительного времени, переносятся из списка Zero Generation в Generation One. Python обрабатывает объекты в списке Generation One аналогичным образом, после того, как значение дельта-значения подсчета распределения достигнет еще более высокого порогового значения. Python перемещает остальные активные объекты в список Generation Two.
Таким образом, объекты, которые ваша программа Python использует в течение длительных периодов времени, что ваш код поддерживает активные ссылки, перейдите от Generation Zero к One to Two. Используя разные пороговые значения, Python обрабатывает эти объекты с разными интервалами. Python обрабатывает объекты в Generation Zero чаще всего, Generation One реже, а Generation Two - реже.
Слабая генерация гипотезы
Такое поведение является основной задачей алгоритма сбора мусора поколения: коллекционер обрабатывает новые объекты чаще, чем старые. Новый или молодой объект - это тот, который ваша программа только что создала, а старый или зрелый объект - тот, который оставался активным в течение некоторого периода времени. Python продвигает объект, когда он перемещает его из Generation Zero в One или от одного до двух.
Зачем это делать? Основная идея этого алгоритма известна как гипотеза слабой генерации . Гипотеза фактически состоит из двух идей: большинство новых объектов умирают молодыми, а старые объекты, вероятно, будут оставаться активными в течение длительного времени.
Предположим, я создаю новый объект с использованием Python или Ruby:
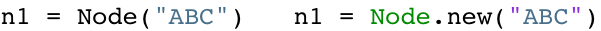
Согласно гипотезе, мой код, скорее всего, будет использовать новый узел ABC только на короткое время. Объект, вероятно, является лишь промежуточным значением, используемым внутри одного метода, и станет мусором, как только метод вернется. Таким образом, большинство новых объектов быстро превратятся в мусор. Иногда, однако, моя программа создает несколько объектов, которые остаются важными в течение более длительного времени - например, переменные сеанса или значения конфигурации в веб-приложении.
Более часто обрабатывая новые объекты в Generation Zero, сборщик мусора Python проводит большую часть своего времени, когда он будет полезен больше всего: он обрабатывает новые объекты, которые быстро и часто становятся мусором. Лишь в редких случаях, когда пороговое значение распределения увеличивается, коллекционер Python обрабатывает старые объекты.
Вернуться к бесплатному списку в Ruby
Предстоящий выпуск Ruby версии 2.1 теперь использует алгоритм сбора коллектора мусора в первый раз! (Помните, что другие реализации Ruby, такие как JRuby и Rubinius, уже много лет используют эту идею.) Вернемся к диаграммам свободного списка из моего последнего сообщения, чтобы понять, как это работает.
Напомним, что когда свободный список используется, Ruby отмечает объекты, которые ваша программа все еще использует:
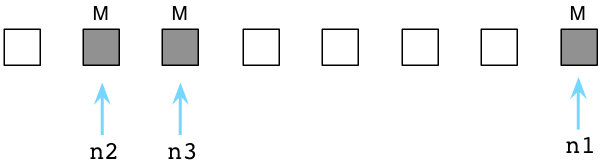
На этой диаграмме мы видим, что есть три активных объекта, потому что указатели n1 , n2 и n3 все еще относятся к ним. Остальные объекты, белые квадраты, являются мусором. (Разумеется, бесплатный список фактически содержит тысячи объектов, которые ссылаются друг на друга в сложных шаблонах. Мои простые диаграммы помогают мне передать основные идеи алгоритма GC Ruby, не увязнув в деталях.)
Также помните, что Ruby перемещает объекты мусора обратно в свободный список, потому что теперь они могут быть переработаны и повторно использованы вашей программой при распределении новых объектов:
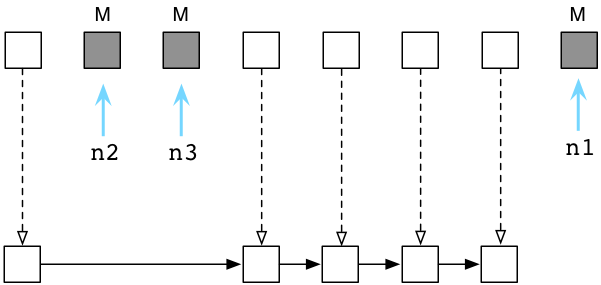
Генерирующий GC в Ruby 2.1
Начиная с Ruby 2.1, код GC выполняет дополнительный шаг: он продвигает оставшиеся активные объекты к зрелым поколениям . (Исходный код MRI C фактически использует слово old и не зрелое .) Эта диаграмма показывает концептуальное представление двух поколений объектов Ruby 2.1:
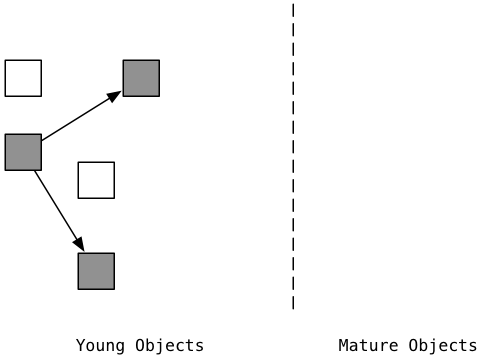
Слева - другой вид бесплатного списка. Мы видим мусорные объекты в белом цвете, а остальные живые, активные объекты серого. Серые объекты были только что отмечены.
Как только процесс маркировки и развертки будет завершен, Ruby 2.1 рассмотрит оставшиеся отмеченные объекты, которые будут зрелыми:
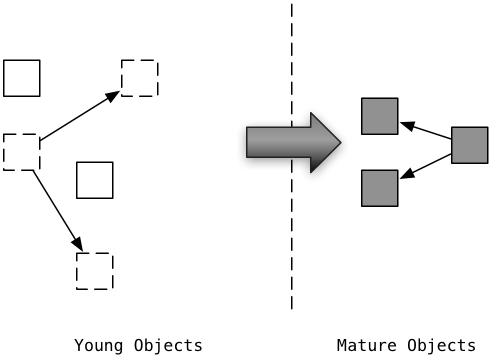
Вместо использования трех поколений, таких как Python, сборщик мусора Ruby 2.1 использует только два. Слева - новые объекты молодого поколения, а справа - старые объекты в зрелом поколении. Как только Ruby 2.1 помечает объект один раз, он считает его зрелым. Ruby делает ставку на то, что объект остается активным в течение достаточно долгого времени, что он не станет мусором быстро.
Важное примечание: Ruby 2.1 фактически не копирует объекты в памяти. Эти поколения не состоят из разных областей физической памяти. (Некоторые алгоритмы GC, используемые другими языками и другими реализациями Ruby, известными как копирование сборщиков мусора , фактически копируют объекты, когда они продвигаются.) Вместо этого Ruby 2.1 использует внутренний код, который не включает ранее отмеченные объекты в методе и процесс развертки еще раз. Как только объект был отмечен один раз, он не будет включен в следующий знак и процесс развертки.
Теперь предположим, что ваша программа Ruby продолжает работать, создавая новые, новые объекты. Они появляются в молодом поколении снова, слева:
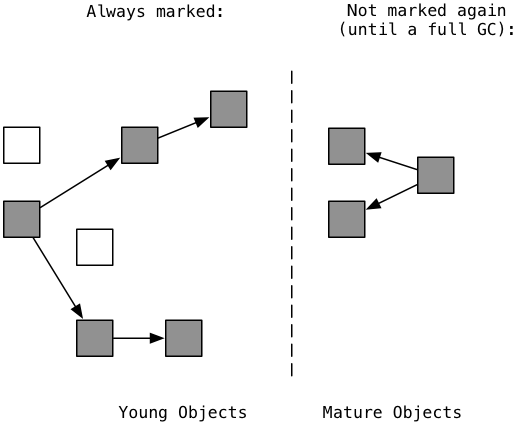
Как и Python, коллекционер Ruby фокусирует свои усилия на молодом поколении. Он включает только новые, молодые объекты, созданные с момента последнего процесса GC в алгоритме метки и развертки. Это связано с тем, что многие новые объекты, скорее всего, будут мусором (белые квадратики слева). Ruby не переопределяет зрелые объекты справа. Поскольку они уже пережили один процесс GC, они, вероятно, останутся активными и не станут мусором в течение более длительного времени. Помечая только юные объекты, код GC Ruby работает намного быстрее. Он просто полностью перескакивает по зрелым объектам, уменьшая количество времени, в течение которого ваша программа ждет завершения сборки мусора.
Иногда Ruby запускает «полную коллекцию», повторную маркировку и перерисовку зрелых объектов. Ruby решает, когда запускать полную коллекцию, контролируя количество зрелых объектов. Когда число зрелых объектов удвоилось со времени последней полной коллекции, Ruby очищает метки и снова рассматривает все объекты молодыми.
Барьеры записи
Один важный вызов этому алгоритму заслуживает дальнейшего объяснения. Предположим, что ваш код создает новый молодой объект и добавляет его как дочерний элемент существующего, зрелого объекта. Например, это произойдет, если вы добавите новое значение в массив, который существовал в течение длительного времени.
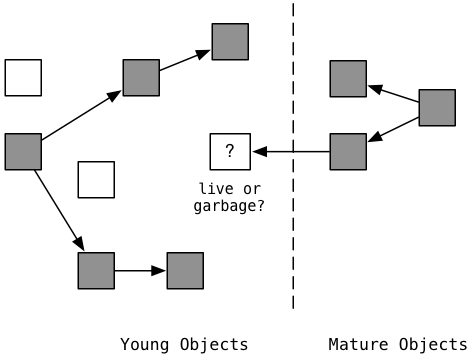
Здесь снова слева мы видим новые, молодые объекты и зрелые объекты справа. С левой стороны процесс маркировки идентифицировал, что 5 новых объектов все еще активны (серые), а два новых объекта - мусор (белый). Но как насчет нового, молодого объекта в центре? Это та, что показана в белом цвете с вопросительным знаком. Является ли этот новый объект мусором или активным?
Он активен, конечно, потому что есть ссылка на него со зрелого объекта справа. Но помните, что Ruby 2.1 не включает зрелые объекты в метку и развертку (пока не произойдет полная коллекция). Это означает, что новый объект будет неправильно считаться мусором и выпущен, в результате чего ваша программа потеряет данные!
Ruby 2.1 преодолевает эту проблему, контролируя зрелые объекты, чтобы увидеть, добавляет ли ваша программа ссылку из них на новый молодой объект. Ruby 2.1 использует старый метод GC, называемый барьерами записи, чтобы отслеживать изменения для зрелых объектов - всякий раз, когда вы добавляете ссылку от одного объекта к другому (всякий раз, когда вы пишете или изменяете объект), запускается барьер записи. Барьеры проверяют, является ли исходный объект зрелым, и если это добавляет зрелый объект в специальный список. Позже Ruby 2.1 включает в себя только эти измененные зрелые объекты в следующем знаке и процессе развертки, не позволяя активным, молодым объектам некорректно считаться мусором.
Фактическая реализация барьеров Ruby 2.1 довольно сложна, прежде всего потому, что существующие расширения C их не содержат. Koichi Sasada и основная команда Ruby использовали ряд умных решений для решения этой проблемы. Чтобы узнать больше об этих технических деталях, посмотрите увлекательную презентацию Koichi от EuRuKo 2013.
Стоя на плечах гигантов
На первый взгляд Ruby и Python, похоже, реализуют сборку мусора очень по-разному. Ruby использует оригинальный алгоритм Mark and Sweep Джона Маккарти, в то время как Python использует подсчет ссылок. Но когда мы смотрим более внимательно, мы видим, что Python использует биты метки и развертки для обработки циклических ссылок, и что Ruby и Python используют коллекцию мусора для генерации аналогичным образом. Python использует три отдельных поколения, в то время как Ruby 2.1 использует два.
Это сходство не должно быть неожиданностью. Оба языка используют компьютерные исследования, которые были сделаны десятилетиями назад - до того, как Ruby или Python были даже изобретены. Мне кажется увлекательным, что, когда вы смотрите «под капотом» на разных языках программирования, вы часто обнаруживаете, что одни и те же фундаментальные идеи и алгоритмы используются всеми из них. Современные языки программирования во многом связаны с фундаментальными исследованиями в области компьютерных наук, которые Джон МакКарти и его современники сделали еще в 1960-х и 1970-х годах.