- Published on
- Updated on
Текстовый редактор: структуры данных
- Authors
Эта публикация - перевод статьи. Ее автор - Avery Laird. Оригинал доступен по ссылке ниже:
Первым шагом в создании текстового редактора является реализация основного API. Если вам интересно, почему я хочу это сделать, см. оригинальную статью здесь.
Я исследовал несколько типов данных и пытался быть независимым от языка. Хотелось, чтобы на мое решение не влиял какой-то конкретный язык, поэтому сначала посмотрим, существует ли «лучший выход», основанный исключительно на операциях. Конечно, «лучший способ» редко достижим. Тем не менее, в случае манипулирования и хранения текста, есть несколько явно «худших» и «лучших» способов.
Худший Путь
Худший способ хранить текст и манипулировать им - использовать массив. Во-первых, сначала необходимо загрузить весь файл в массив, что вызывает проблемы со временем и памятью. Что еще хуже, каждая вставка и удаление требуют перемещения каждого элемента в массиве. Есть и другие недостатки, но уже этот метод явно не практичен. Массив может быть отклонен как опция довольно быстро.
Кстати, это не вызов. Пожалуйста, не пытайтесь найти худшие способы манипулирования текстом.
Хороший путь
Другой вариант - бинарная древовидная структура, называемая веревкой. Перейдите к следующему разделу, если двоичные деревья вам не подходят.
Если вы не знакомы с бинарными деревьями, возьмите это как отправную точку.
По сути, строка разбивается на разделы и сохраняется в листьях. Вес каждого листа - это длина сегмента струны. Вес каждого неконечного узла - это общая длина строк в его левом поддереве. Например, на диаграмме ниже узел E – это лист с сегментом длиной 6 символов. Следовательно, он имеет вес 6 – также как и его родительский узел. Тем не менее, узел B имеет вес 9, потому что узлы Е и F вместе имеют длину 9.
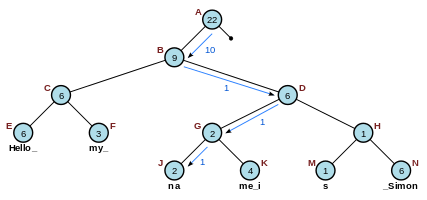
Это намного эффективнее, чем массив. Веревка имеет две основные операции, Split и Concat (сцепление). Split разбивает одну строку на две строки с заданным индексом, а Concat объединяет две строки в одну. Вы можете предварительно выполнить вставку или удаление с помощью одной из этих двух основных операций. Чтобы вставить символы, можно разделить строку единожды (там, где вы хотите вставить содержимое) и объединить ее дважды (по обе стороны от вставленного содержимого). Удаление работает аналогично: дважды разбивается строка и снова объединяется, не включая удаленный контент.
Есть большой недостаток. Использование веревки довольно запутанно и сложно. Это сложно объяснить даже абстрактно. Разрабатывать изломы в реальной жизни, в то же время делая код поддерживаемым и читабельным – кажется, это ад. Более того, он по-прежнему занимает много места. Это еще не самый лучший вариант, поэтому я продолжал искать.
Лучший путь
Gap Buffer гораздо проще, чем веревка. Идея такова: операции над текстом часто локализованы. Большую часть времени мы не перемещаемся по всему документу. Итак, мы создаем «пробел» между символами, хранящимися в массиве. При этом, отслеживаем, насколько велик разрыв, используя указатели или индексы массивов. Давайте рассмотрим два случая (с использованием указателей):
Вставка: разрыв определенного размера для начала. Мы копируем вставленный контент. Если он превышает размер пробела – увеличиваем пробел.
Делеция: мы сдвигаем указатели разрыва, чтобы включить удаленный контент.
В этом есть большой смысл. Мы несколько страдаем от тех же проблем, что и массив; при определенных обстоятельствах, если мы переместимся слишком далеко от промежутка, каждый элемент в массиве должен будет быть перемещен. Тем не менее, наиболее вероятно, что это редкое явление для обычного пользователя. Вполне возможно, что скорость, полученная при большинстве операций, перевесит неэффективность некоторых крайних случаев. На самом деле, приложение, в котором я пишу, Emacs, использует буфер пробелов, и это, вероятно, самый быстрый текстовый редактор, который я когда-либо использовал. Уже один этот факт является довольно убедительным аргументом в пользу использования гэп-буфера. Но если я начинаю с нуля, я хочу, чтобы каждый аспект программного обеспечения был лучшим вариантом. И, может быть, есть лучший способ.
Лучший метод
Пару месяцев назад мой папа попросил меня помочь с проблемой. Он конвертировал одну из своих книг в markdown, при этом была проблема с сносками. В markdown сноски не нумеруются автоматически; они должны быть помечены либо цифрой, либо текстом, например: [^1] или [^footnote]. Определение то же самое, с двоеточием в конце.
Он использовал pandoc для преобразования документа, но в каждой сноске был формат [^#]. Моя работа заключалась в том, чтобы сделать скрипт для замены каждого # числом, начиная с 1.
Легко, правда?
Ну вот и я так думал. Я набрал регулярное выражение, отсканировал документ и заменил все вхождения шаблона увеличивающимся целым числом. И это произвело мусор.
Почему? Потому что я сделал очень, очень очевидную ошибку. Счетчик не всегда занимает одинаковое количество места. Сценарий продолжал перезаписывать содержимое, и смещение увеличивалось по мере замены сносок. Есть простое решение: отследить, сколько места занято, и добавь это к вашей текущей позиции в документе. Я сделал это одно простое изменение, и все работало отлично. Не зная об этом в то время, я использовал Piece table.
Страница Википедии для Таблицы фигур занимает всего 8 строк (Yikes!). Еще более важно то, что Microsoft Word упоминается среди редакторов, использующих таблицы фигур. Тем не менее, поштучная таблица – очень многообещающая структура. Более того, в своей концепции Word был молниеносным с бесконечным повторением / отменой, как объяснялось в этой интересной статье разработчика Microsoft. Если у вас есть время, прочтите обязательно.
В 1998 году Чарльз Кроули написал статью, в которой исследовал достоинства и недостатки различных структур данных, используемых в текстовых редакторах. Его статья включает в себя структуры: буферы разрыва, массивы и веревки. Он пришел к выводу, что - исходя из скорости, простоты и структуры - таблица фигур была ведущим методом. С моей точки зрения, Piece table также является самым элегантным решением.
Нам нужны два буфера: исходный файл (только для чтения) и новый файл, который будет содержать весь добавленный текст. Наконец, у нас есть таблица с 3 столбцами: файл, начало, длина. Это файл, который нужно использовать (оригинальный или новый), где сегмент текста начинается в каждом файле (перед редактированием) и длина сегмента. Вот пример:
Original File: A_large_span_of_text (underscores denote spaces)
New File: English_
File Start Length
-----------------------------------
Original 0 2
Original 8 8
New 0 8
Original 16 4
Sequence: A_span_of_English_text
Имейте в виду, что индекс Start не относится к предыдущим изменениям. Это то, что обрабатывается во время выполнения путем добавления длины каждого предыдущего редактирования. Поскольку длина уже включена в таблицу, это тривиальный шаг.
Мне это решение нравится больше всего, потому что:
- Оно элегантно. Записывается только минимальный объем информации.
- Оно простое. Только необходимые операции. Нам не нужно перебалансировать или пересекать двоичное дерево.
- Оно быстрое. Решение может быть молниеносным. Есть несколько дополнительных оптимизаций.
Метод piece table, безусловно, имеет свои сложности, и существуют разные варианты его реализации. Это, безусловно, сложная задача. Посмотрим, как далеко я зайду. Другая статья будет сопровождать мои попытки реализовать метод piece table.